When working with PyTorch, a GPU (Graphics Processing Unit) can significantly enhance your model’s training speed by performing parallel computations.
Use PyTorch’s torch.cuda.is_available() function to see if a GPU is available. This function returns True if PyTorch detects a CUDA-capable GPU, allowing you to leverage GPU acceleration for your models. For more details, visit PyTorch Documentation.
In this article, we will explain how to determine GPU availability and how to use it effectively in PyTorch.
What Is PyTorch GPU Support?
PyTorch is a deep learning framework that supports CPU and GPU computing. It is designed to take advantage of GPUs for faster training and inference.
With GPU acceleration, models can run hundreds of times faster than only CPUs. In PyTorch, the primary library for GPU acceleration is CUDA, an Nvidia-specific library allowing code to run on Nvidia GPUs.
PyTorch runs on the CPU by default, but if CUDA-enabled GPUs are available, you can switch to GPU to speed up your operations.
How to Check If GPU Is Available in PyTorch?
Checking for GPU availability in PyTorch is straightforward. PyTorch provides the torch.cuda.is_available() function to verify whether a CUDA-capable GPU is available. Here’s an example:
import torch
print(torch.cuda.is_available())
A CUDA-capable GPU is available on your system if this function returns True. If it returns False, you either don’t have a GPU, or it’s not set up correctly. Ensure your Nvidia drivers and CUDA toolkit are installed correctly so that PyTorch can detect the GPU.
How to Print GPU Information in PyTorch?
You can print detailed GPU information using torch.cuda.get_device_name() and torch. cuda.device_count() methods. Here’s how you can retrieve this information:
if torch.cuda.is_available():
print(torch.cuda.get_device_name(0))
print(“Number of GPUs:”, torch.cuda.device_count())
The output will display the name of the first GPU in your system and the total number of GPUs available. For instance, if you have a Nvidia RTX 3080, you will see the name of the GPU printed on your console.
How to Set Up Tensors for GPU in PyTorch?
Once you have confirmed the GPU’s availability, the next step is to ensure your tensors are loaded onto the GPU. You can do this by specifying the device parameter when creating tensors. For example:
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
x = torch.tensor([1.0, 2.0, 3.0], device=device)
print(x.device)
This code snippet ensures that the tensor is created on the GPU (if available) and prints the device on which the tensor resides.
Also Read: GPU Junction Temperature – How It Affects Performance – 2024
How to Move Tensors to GPU?
If you have already created tensors on the CPU, you can move them to the GPU using the .to() method or the .cuda() method. Here is an example:
x = torch.tensor([1.0, 2.0, 3.0])
x = x.to(“cuda”) # Moves tensor to GPU
print(x.device)
Alternatively, using .cuda():
x = torch.tensor([1.0, 2.0, 3.0])
x = x.cuda() # Moves tensor to GPU
print(x.device)
Both methods will transfer the tensor from the CPU to the GPU. When no GPU is available, handle the transfer properly to avoid CUDA errors.
How to Check the Current Device?
You can check which device (CPU or GPU) a tensor is located on by printing the tensor’s .device property. This is useful for ensuring that your operations are performed on the correct device. Here’s an example:
x = torch.tensor([4.0, 5.0, 6.0], device=”cuda”)
print(x.device)
The output will indicate whether the tensor is on the CPU or a specific GPU (e.g., cuda:0).
Also Read: Is 82 Degrees Hot For GPU? – The Latest Overview In 2024!
How to Use Multiple GPUs in PyTorch?
For systems with multiple GPUs, PyTorch offers options to distribute computations across several GPUs, which can further accelerate training. You can specify the GPU index when transferring data or running models on specific devices. For example:
x = torch.tensor([1.0, 2.0, 3.0])
x = x.to(“cuda:1”) # Transfers tensor to the second GPU
print(x.device)
You can also parallelize model training using PyTorch’s DataParallel class to distribute the workload across multiple GPUs.
How to Use GPU for Model Training in PyTorch?
To use the GPU for model training, you must transfer both the model and the input data to the GPU. Here’s how you can train a simple model on the GPU:
model = MyModel().to(device) # Transfer model to GPU
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(epochs):
inputs, labels = inputs.to(device), labels.to(device) # Transfer data to GPU
optimizer.zero_grad()
outputs = model(inputs)
loss = criteria (labels, outputs)
loss.reverse()
optimizer.step()
This example shows how to move the model and data to the GPU, ensuring that the computations occur on the GPU for faster processing.
Common Errors When Using PyTorch with GPUs
Working with GPUs in PyTorch is relatively straightforward, but users may encounter some common errors, such as:
- CUDA Out of Memory Error: occurs when your model or data is too large for the available GPU memory. To avoid this error, you can reduce batch sizes or optimize your model.
- Device Mismatch Error: This error occurs when trying to perform operations on tensors located on different devices (e.g., a tensor on the CPU and another on the GPU). Ensure all tensors involved in an operation are on the same device.
Must Read: Nvidia G Sync With AMD GPU – Boost Gaming Performance!
Best Practices for Using GPUs in PyTorch
When using PyTorch with GPUs, there are several best practices to keep in mind:
- Efficient Memory Usage: GPUs have limited memory, so memory-efficient techniques such as gradient checkpointing or model quantization are used to reduce memory consumption.
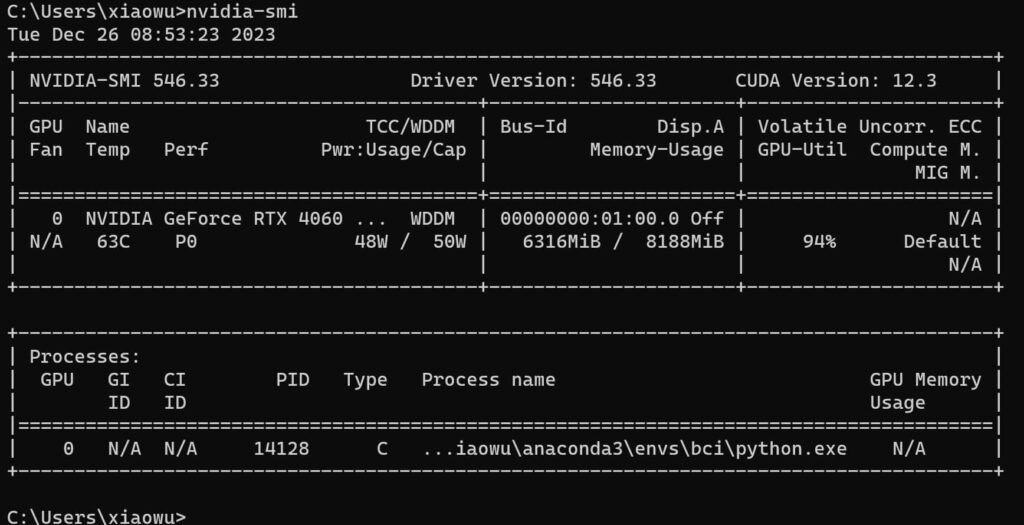
- Monitor GPU Usage: Use tools like Nvidia’s nvidia-semi to monitor GPU usage, memory consumption, and temperature during training.
- Mixed Precision Training: Leverage PyTorch’s mixed precision training (torch.cuda.amp) to improve performance using 16-bit floating-point numbers instead of 32-bit numbers.
By following these best practices, you can maximize the performance of your PyTorch models and avoid common pitfalls when using GPUs.
PyTorch Install
To install PyTorch, go to pytorch.org, select your system settings, and run the generated command in your terminal. PyTorch supports multiple platforms and ensures GPU acceleration with CUDA during installation.
Torch.cuda.is_available() False
If torch.cuda.is_available() returns false, which means PyTorch isn’t detecting your GPU. Ensure you have installed the correct Nvidia drivers and CUDA toolkit, and confirm your GPU is correctly set up to enable GPU support.
PyTorch Not Using GPU
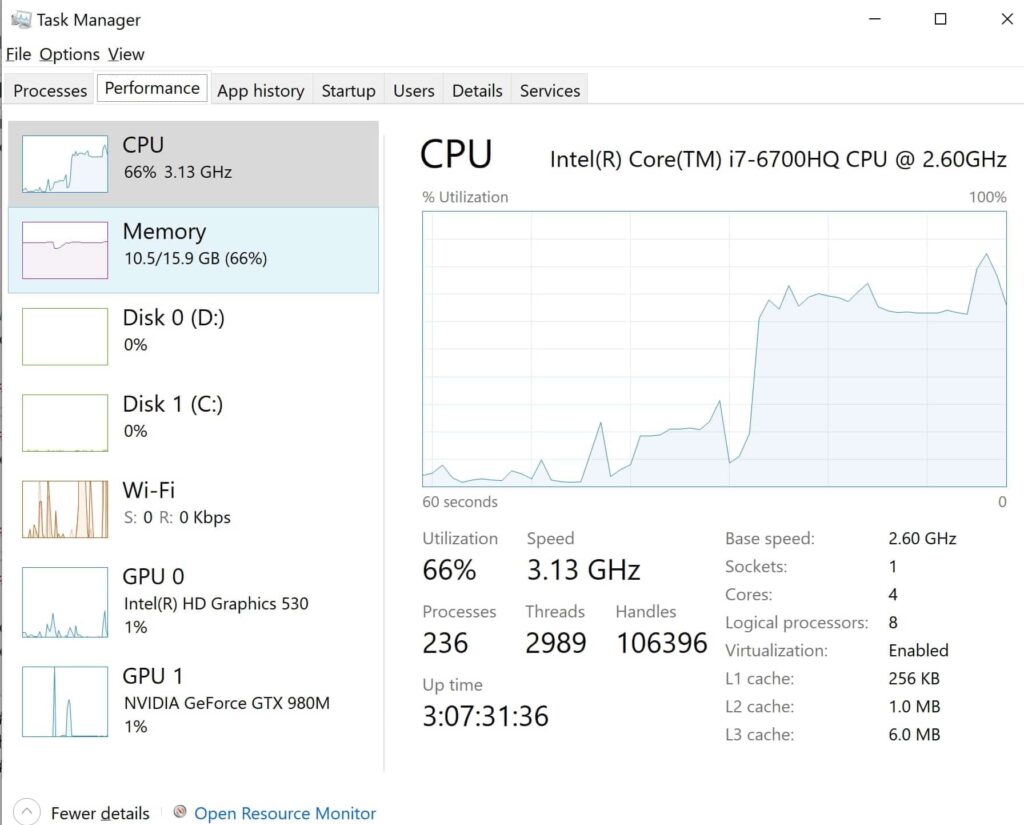
If PyTorch isn’t using your GPU, check if CUDA is installed correctly, and ensure your model and tensors are moved to the GPU using .cuda() or .to(‘cuda’). Also, verify that the GPU is enabled in your code.
PyTorch GPU
PyTorch can leverage the GPU for faster computations, and using CUDA can significantly speed up model training. Always check GPU availability with a torch.cuda.is_available() and transfer data and models to the GPU.
PyTorch GPU Install
To install GPU support in PyTorch, you need CUDA. Visit pytorch.org, select the CUDA version during installation, and ensure the necessary drivers are installed so your Nvidia GPU works correctly.
Torch CUDA Not Available
If torch.cuda isn’t available; your system either lacks the necessary Nvidia drivers and CUDA toolkit or doesn’t have a GPU. Install the correct versions of CUDA and drivers or verify your hardware setup for GPU acceleration.
FAQs
1. Is a GPU Available?
To check GPU availability in PyTorch, use a torch.cuda.is_available(). It returns True if a GPU is present.
2. How to Check GPU Availability in Python?
In Python, use PyTorch’s torch.cuda.is_available() function to check if your system has a CUDA-capable GPU installed.
3. How to Make Sure PyTorch Uses GPU?
Ensure your tensors and model are moved to the GPU using .cuda() or .to(‘cuda’) in PyTorch.
4. How Do I Check My GPU Status?
Check GPU status using PyTorch with a torch.cuda.get_device_name(0) to view your active GPU’s name and details.
5. How to Monitor GPU Usage in PyTorch?
Use Nvidia-semi to monitor GPU usage. It shows memory usage, temperature, and GPU activity during PyTorch operations.
6. How Do I Know If I Have GPU?
Use torch.cuda.is_available() in PyTorch to check if your system has a CUDA-capable GPU for acceleration.
7. Programmatically Check If PyTorch Is Using a GPU?
Check if PyTorch uses a GPU by printing the tensor’s .device attribute or using a torch.cuda.is_available() for confirmation.
8. How to Check If PyTorch Is Using the GPU?
Ensure PyTorch uses the GPU by checking the tensor’s device with .device or confirming with a torch.cuda.is_available().
9. PyTorch Cannot Find GPU, 2021 Version.
If PyTorch cannot detect your GPU, update your drivers, install the CUDA toolkit, and ensure PyTorch is correctly installed.
10. Torch.cuda.is_available() is True While I Am Using the GPU
If torch.cuda.is_available() is accurate, your GPU is being detected. Ensure data and models are transferred to the GPU properly.
Conclusion
In conclusion, checking GPU availability in PyTorch is essential for optimizing model performance. You can significantly enhance training speed and efficiency by utilizing functions like `torch.cuda.is_available()` and properly transferring models and data to the GPU. Following best practices ensures practical GPU usage for deep learning tasks.